

Des projets
qui transforment !

Chez Fractus, chaque intervention vise un impact tangible sur la performance industrielle. Découvrez quelques-unes de nos réalisations qui ont permis à nos clients de dépasser leurs blocages, d’optimiser leurs opérations et de sécuriser leurs transformations.





Sécuriser l’exploitation d’un métro automatisé
avec une approche MBSA* de haut niveau

*MBSA : Analyse de la Sûreté de fonctionnement basée sur les modèles
Contexte industriel
Dans le cadre de la modernisation d’un réseau de métro, un opérateur majeur du transport urbain prévoit le déploiement progressif de nouvelles rames automatisées (niveaux d’automatisation GOA4 et GOA2) sur 8 lignes, d’ici 2030. Cette évolution s'accompagne d’un renforcement de la complexité des systèmes de contrôle-commande, nécessitant une meilleure maîtrise des risques techniques et d’exploitation.
Le besoin du client
Le client souhaite améliorer la sûreté de fonctionnement de ses lignes automatisées tout en limitant les coûts liés aux pannes et aux situations dégradées. Pour cela, il veut se doter d’un outil d’analyse modulaire et réutilisable, capable d’évaluer de manière robuste et rapide différentes variantes de son système global d’exploitation (SGE), en s’appuyant sur une démarche MBSA (Model-Based Safety Assessment).
Notre approche
Fractus et son partenaire EdgeMind ont conçu et mis en œuvre une démarche de modélisation haut niveau du SGE, s’appuyant sur :
-
- une bibliothèque de composants métiers développée sous Altarica 3, réutilisable sur différents cas d'étude,
- des modèles génériques de ligne automatisée et semi-automatique intégrant les aspects fonctionnels et dysfonctionnels du système,
- un ensemble d’analyses FMD (Fiabilité, Maintenabilité, Disponibilité) sur différentes variantes du système,
- une documentation structurée et un support de formation pour garantir la montée en compétence des équipes internes.
Résultats obtenus
- 2 bibliothèques de composants modélisant le SGE pour GOA4 et GOA2
- 4 modèles systèmes paramétrables et évolutifs
- 6 notes d’analyse (fonctionnelle, FMD, techniques)
- Un outil de simulation adapté au SGE
- Un support de formation complet
Gain client obtenus
Simulation de défaillances
dans un réseau électrique industriel complexe
Contexte industriel
Dans une démarche globale de modernisation et de sécurisation de ses infrastructures critiques, la direction d’un site industriel stratégique a souhaité évaluer la robustesse de son réseau électrique. L’alimentation du site repose sur une architecture complexe, reconfigurable et en partie redondée, intégrant des connexions aux réseaux publics (ENEDIS, RTE) ainsi que des systèmes internes de secours.
L’objectif était d’anticiper les risques de coupures, d’identifier les points sensibles et de proposer des pistes d’amélioration de l’architecture pour garantir la continuité de service.
Le besoin du client
Le client souhaitait une évaluation externe indépendante de la fiabilité et de la disponibilité de ses infrastructures électriques, prenant en compte différents scénarios d’utilisation, configurations d’exploitation et niveaux de criticité.
Cette évaluation devait permettre :
-
- d’objectiver la robustesse des architectures envisagées,
- d’identifier les équipements les plus critiques,
- et de proposer des leviers d'amélioration ou de sécurisation si nécessaire.
Notre approche
Nous avons appliqué une méthodologie de modélisation dynamique à base de chaînes de Markov pour simuler le comportement dégradé de l’infrastructure sur différents niveaux :
-
-
Équipements clés : modélisation détaillée de composants spécifiques à haute criticité.
-
Architecture électrique : modélisation des interconnexions, des redondances et des logiques de bascule.
-
Cas d’usage réalistes : intégration des environnements, des contraintes d’exploitation et des profils de charge.
-
Les modèles ont pris en compte différents types de défaillances : pannes matérielles internes, erreurs fonctionnelles ou logicielles, erreurs humaines. Nous avons conçu des simulateurs sur mesure permettant de générer des indicateurs quantitatifs tels que la fiabilité (MTBF), la disponibilité ou les temps de récupération.
Résultats obtenus
- Cartographie complète des états de fonctionnement nominaux et dégradés du réseau.
- Évaluation quantitative des MTBF et taux de disponibilité pour chaque infrastructure.
- Identification des points de vulnérabilité critiques dans l’architecture.
- Recommandations ciblées d’optimisation (modifications d’architecture, gestion des interfaces, redondances spécifiques).
- Support à la décision pour arbitrer entre plusieurs solutions d’architecture.
Gain client obtenus
Réduire les délais de production
Analyse du lead time d’usine pour optimiser flux, encours et organisation industrielle
Contexte industriel
Un fabricant de composants mécaniques de haute précision, travaillant en production à la commande pour l’aéronautique et l’automobile, faisait face à une augmentation de ses délais de production, impactant directement la satisfaction de ses clients.
L’usine, organisée autour de plusieurs ateliers spécialisés et zones de stockage intermédiaires, souffrait d’un manque de visibilité sur ses goulots d’étranglement. Malgré des investissements récents dans de nouvelles machines, le lead time global continuait d’augmenter, atteignant jusqu’à +25 % au-dessus des objectifs.
Le besoin du client
Le client avait besoin :
-
- d’identifier les causes des retards et de la variabilité des délais,
- de tester différents scénarios d’organisation industrielle,
- et de mesurer l’impact de changements (capacité machine, organisation des équipes, horaires, flux logistique) avant mise en œuvre réelle.
L’enjeu était clair : réduire les délais moyens tout en augmentant la capacité de réponse aux variations de la demande, sans dégrader la qualité.
Notre approche
Nous avons conçu une simulation dynamique avec interface graphique en utilisant le langage formel Sigma (outil WordLab de Systemic Intelligence). La modélisation a intégré les chaînes de production complètes, incluant capacités machine, ressources humaines, zones de stockage et flux logistiques comme illustré dans le schéma suivant :
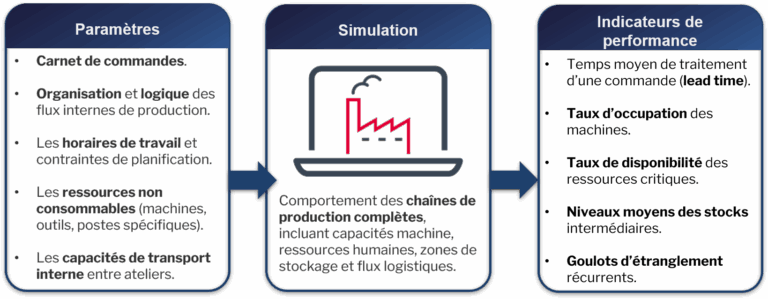
Nous avons simulé plusieurs scénarios :
-
- Organisation actuelle (situation de référence).
- Augmentation de capacité sur les ateliers critiques.
- Réorganisation des horaires d’équipes pour lisser la charge.
- Optimisation des flux logistiques internes (réduction des déplacements inutiles).
- Simulation de variations de carnet de commandes (croissance +15 %, baisse -10 %).
Les indicateurs analysés :
-
- Temps moyen de traitement d’une commande (lead time).
- Taux d’occupation des machines.
- Taux de disponibilité des ressources critiques.
- Niveaux moyens des stocks intermédiaires.
- Goulots d’étranglement récurrents.
Résultats obtenus
- Cartographie précise des flux et ressources critiques de l’usine.
- Identification de 2 goulots majeurs responsables de 60 % des retards.
- Validation que l’ajout d’une machine sur un atelier clé réduisait le lead time de 18 %.
- Démonstration qu’une meilleure répartition horaire des équipes permettait de réduire les pics de charge et d’éviter la surcharge machine.
- Visualisation claire des impacts sur stocks intermédiaires et flux logistiques.
Gain client obtenus
Tester la résilience système
Évaluation de la capacité du système d’urgence britannique à absorber un afflux massif d’appels.
Contexte industriel
Le système d’appel d’urgence en Angleterre repose sur un réseau de centrales réparties dans différentes comtés. Ce dispositif doit assurer un temps de réponse minimal aux situations critiques, allant des accidents de la route aux événements majeurs comme des attaques terroristes. Les autorités ont exprimé la volonté d’évaluer la résilience du système face à des scénarios extrêmes et de repenser son organisation pour limiter le risque de saturation.
Le besoin du client
Les services d’urgence souhaitaient :
-
- Évaluer la capacité actuelle des centrales d’appel à absorber un pic de demande.
- Identifier les points de saturation en cas de crise majeure.
- Mesurer l’impact d’une redistribution des appels entre comtés.
- Tester des scénarios variés (accidents isolés, catastrophes multiples, événements exceptionnels) pour anticiper les taux d’appels manqués et les temps d’attente.
Notre approche
Nous avons développé un double modèle de simulation :
La modélisation a pris en compte :
-
- Les temps moyens d’attente en file d’attente par type d’appel.
- Les ressources humaines disponibles par centrale (opérateurs par tranche horaire).
- Les capacités maximales de traitement simultané.
- Les règles de redirection des appels vers d’autres comtés.
- Les délais de réaction en cas de surcharge.
Plusieurs scénarios ont été testés :
-
- Situation nominale (répartition actuelle des appels).
- Crise localisée (accident majeur dans un comté spécifique).
- Crise multi-sites (ex. : tempête ou inondations sur plusieurs comtés).
- Événement exceptionnel national (attentat terroriste dans une capitale).
Résultats obtenus
-
- Mise en évidence de seuils critiques à partir desquels la file d’attente moyenne dépasse 2 minutes.
- Identification de comtés sous-dimensionnés, présentant jusqu’à 35 % d’appels manqués en cas de crise majeure.
- Confirmation que la redirection intelligente des appels permet de réduire jusqu’à 50 % le nombre d’appels non traités.
- Détermination des configurations optimales pour maximiser la résilience avec un effectif limité.
De futures réalisations prochainement publiées
Cette page internet est en cours de rédaction, elle sera disponible prochainement (Dealine - septembre 2025)
Merci de votre compréhension.